Обсуждение участника:Kostinm (KQvr';yuny rcgvmuntg&Kostinm)
Добро пожаловать, Kostinm!
От имени участников Википедии приветствую вас в её разделе на русском языке. Надеемся, вы получите большое удовольствие от участия в проекте.
Обратите внимание на основные принципы участия: правьте смело и предполагайте добрые намерения.
Полезные для вас страницы:

Статьи в Википедии не подписываются (список авторов формируется автоматически и доступен в истории правок статьи); в обсуждениях при редактировании кода, пожалуйста, ставьте после сообщения четыре тильды (~~~~): они будут автоматически преобразованы в подпись и дату.
На своей личной странице вы можете сообщить некоторые сведения о себе — например, владение языками или интересы.
Если у вас возникли вопросы, воспользуйтесь справочными материалами. Если вы не нашли в них ответа на ваш вопрос, задайте его своему наставнику через «Домашнюю страницу» или через панель помощи при редактировании статьи. Также можно обратиться на форуме помощи.
Если вы не можете создать статью одной правкой и намерены вернуться к её написанию позже, поставьте в начало текста шаблон {{subst:Редактирую}} для уведомления об этом других участников.
И ещё раз, добро пожаловать!
Hello and welcome to the Russian Wikipedia! We appreciate your contributions. If your Russian skills are not good enough, that’s no problem. We have an embassy where you can inquire for further information in your native language. We hope you enjoy your time here!
`a5b (обс.) 16:54, 26 декабря 2019 (UTC)
75 dgx-2 & flops
[править код]Привет, спасибо за правки. В FLOPS вы указали на 75 узлов в Кристофари - как именно вам удалось подсчитать их количество? В текущих источниках явно 75 не прописано, число немного странное, т.к. нечетное (неясна топология сети). Называть fmac 128 и 256 битным не вполне корректно, т.к. формат обрабатываемых данных лишь 64 бита. С турбобустом не все так просто - некоторые из автоподстроек частоты вполне можно выводить на максимум при постоянном обеспечении низкой температуры; лучше приводить максимальную производительность не рассчитанную самостоятельно, а по источникам, в частности из APP calculations (“Adjusted Peak Performance”) - https://www.intel.com/content/www/us/en/support/articles/000005755/processors.html (EAR 15 CFR, December 2006 Wassenaar Arrangement Plenary Agreement Implementation, EAR 71 CFR 20876 Weighted Teraflops, https://www-03.ibm.com/products/exporting/) `a5b (обс.) 16:54, 26 декабря 2019 (UTC)
Приветствую.
По топологии сети кластера у меня нет информации. Но про 75 узлов есть информация на официальном сайте Сбербанка посвященном этому кластеру. Правда не в виде текстовых спецификаций, а в видеоролике с его презентации: https://sbercloud.ru/christofari (по кнопке "Хочешь узнать больше?")
Мне казалось она уже была в источниках, но видимо я туда не напрямую из Вики перешел, а сначала через сайт TOP-500. Сейчас добавлю прямую ссылку в источники.
Так же число узлов можно рассчитать самостоятельно исходя из заявленной конфигурации в официальной карточке проекта на TOP-500 (https://www.top500.org/system/179778) и спецификаций использованных узлов (https://dgx-systems.ru/dgx-2):
Объем памяти 115200 ГБ = 112.5 ТБ, количество вычислительных ядер = 99600
Объем памяти установленной в одном NV DGX-2 = 1.5 ТБ.
112.5/1.5 = 75 узлов DGX-2
Количество вычислительных ядер в NV DGX-2 = 2*24+16*80 = 1328 (2 центральных процессора Xeon Platinum 8168 24C + 16 векторных ускорителей Tesla V100 обладающих 80 вычислительными модулями/ Compute Units).
99600/1328 = 75 узлов DGX-2
Насчет "широких" FMAC. Их использование не ограничено строго 64 битным форматом данных. В соответствующих наборах команд (например AVX) есть отдельные инструкции для работы со 128 битными и 256 битными операндами соответственно. Т.е. как минимум часть операций можно выполнять не только в режиме упаковки данных как 4х32, 2х64 в FMAC-128 или 4х64 на FMAC-256 (собственно SIMD - одна инструкция, выполняющая операцию над несколькими операндами), но и непосредственно с данными шириной в 128 бит и 256 бит соответственно, т.е. 1 операнд длинной в 128 или 256 бит.
По частотам вопрос конечно спорный, но даже при работе на базовых частотах с хорошо оптимизированным SIMD кодом (на котором только и возможно получение результатов близким к теоретическим) современные процессоры уже превышают расчетные показатели по потреблению энергии и нагреву. Заставить работать на частотах выше базовой в принципе возможно, но это требует снятия программных ограничений по TDP(на "потребительских" платах в отличии от серверных это зачастую сделано по умолчанию производителями мат. плат - отсюда частые в последнее время жалобы пользователь на то, почему их процессор так сильно греется, хотя указана мощность например всего в 65 Вт) и усиленного охлаждения. Даже на базовой частоте превышение существенное, поэтому без снятия ограничений по нагреву/TDP многие процессоры при такой нагрузке снижают частоты ниже базовой, например представители микроархитектур Intel Haswell и Broadwell. Т.е. работа на частотах выше базовой при подобных нагрузках по сути является эквивалентом разгона (нештатного и не гарантированного производителем использования оборудования).
В вашем источнике по сути идет такой же теоретический расчет исходя из базовая частота*количество ядер*количество FPU в ядре*ширина FPU/64*2, хотя явно это и не указано. Например:
7th Generation Intel® Core ™ i7 Processors I7-7700K 268.8 GFLOPS
4.2*4*2*256/64*2 = 268.8
8th Generation Intel® Core ™ i7 Processors I7-8700K 355.2 GFLOPS
3.7*6*2*256/64*2 = 355.2
Т.е. в расчет принимается только базовая частота процессора заявленная производителем и его архитектурная конфигурация FPU модулей. Просто для удобства клиентов уже проведены все расчеты и приведен итоговой результат. Конкретно для Intel процессоров можно ссылаться и на эти таблицы, но для других производителей микропроцессоров я таких таблиц не встречал. К тому же теоретический расчет по формуле позволяет читателю понять (и самостоятельно проверить) откуда все эти числа изначально берутся.
P.S.
Хотя для наиболее производительных решений частоты в официальном расчете взяты существенно ниже базовой. Например:
Intel® Core ™ X-series Processors I9-7900X 800 GFLOPS
2.5*10*2*512/64*2 = 800
Хотя базовая частота данного процессора = 3.3 ГГц, а турбо до 4.3 ГГц. Но под AVX-512 нагрузкой процессоры данного семейства (Skylake-X) снижают частоты существенно ниже базовой (в данном случае до 2.5 ГГц), чтобы избежать экстремального нагрева и перегрузки цепей питания. Принудительный возврат хотя бы базовой частоты со стороны пользователя в данном случае уже является нештатным разгоном процессора и требует усиленных цепей питания на материнской плате и усиленного охлаждения.
Максим (обс.) 19:55, 26 декабря 2019 (UTC)
Еще информация по теме пиковой производительности и ее связи с частотой и TDP на современных процессорах. Как раз читал обзор по новому HEDT процессору c оснащенному двумя FMAC-512 Intel Core i9-10980XE.
Частоты заявленные производителем составляют 3 ГГц базовая, 4.6 ГГц турбо. Но при работе с 256 битными инструкциями (AVX/AVX2) частоты снижаются на 500 МГц, а при работе с 512 битными (AVX-512) на 1000 МГц. И даже эти урони требуют снятия ограничений по TDP, с соответствующим повышенным потреблением энергии и нагревом.
При наличии штатных ограничений частота работы снижается до всего 2.3 ГГц - только в таком режиме процессор может уложиться в заявленные для него 165 Вт мощности. Скорее всего именно эту частоту потом Intel будет использовать для расчета пиковой производительности при очередном обновлении таблиц.
А работа хотя бы на базовой частоте с AVX512 будет уже довольно экстремальным разгоном. В обзоре выше работа с AVX-512 на частоте 3.2 ГГц (всего на 7% выше базовой) вызывало более чем двукратное превышение потребления энергии (~410 Вт против официальных 165 Вт) и разогрев до 107 градусов несмотря на использование хорошего водяного охлаждения.
Максим (обс.) 23:42, 26 декабря 2019 (UTC)
- По поводу "fmac 128 и 256 битным не вполне корректно" - может там в avx где-то и есть широкие синтетические операнды, но явно не для всех операций. Нативно реализованы fp mul, fp add операции IEEE 754-2008 над типами float32, float64 (binary32, binary64) (иногда float16) но не над более широкими: https://en.wikichip.org/wiki/x86/avx-512 "AVX-512 is a set of 512-bit SIMD extensions that allow programs to pack .. eight double-precision floating-point numbers, .. within 512-bit vectors." Мы достоверно не знаем как именно эти fmac реализованы внутри, но в силу отсутствия нативных binary128 fp операций можно предположить что это multi-lane векторное устройство с нативными умножителями float64 (и изредка их можно переиспользовать для int52 на int52 -> 104bit - Cannonlake CPU, avx512-ifma: vpmadd52luq + vpmadd52huq). Источники не употребляют "fmac-512" `a5b (обс.) 01:08, 27 декабря 2019 (UTC)
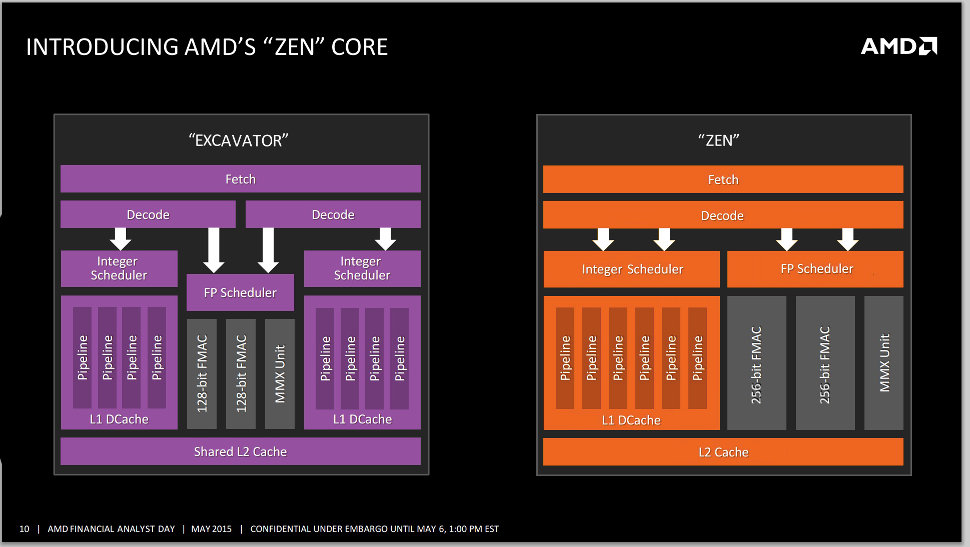
Да, действительно для длинных операндов далеко не все операции доступны, например произвольное перемножение/деление над числами с плавающей точкой доступно только до 64 бит максимум. Но часть операций доступно и 128/256 бит. Например такие операции как копирование/перенос между регистрами, обмена старшей/младшей части длинного операнда в регистре, загрузка/выгрузка из/в память сразу по 128/256 бит одной командой(и за 1 такт), часть целочисленных операций, а так же почти все битовые операции типа побитового сравнения операндов или битового сдвига (что можно среди прочего использовать для замены умножения или деления на множители кратные степени двойки). Т.е. это и не полноценные блоки работающие со 128/256/512 бит математикой, но и все-таки и не просто набор из 2/4/8 отдельных 64 битных блоков объединенных только логически(на уровне набора инструкций). FMAC-512 поэтому может писать и не корректно, но и FMAC-64x8 это тоже будет некорректно, в результате как это кратко и при этом корректно обозначить - не ясно. Для 128 и 256 бит сокращения FMAC-128 и FMAC-256 вполне используются, для 512 бит FPU блоков Intel сейчас использует более обтекаемое обозначение их как "AVX-512 FMA Units". — Максим (обс.) 18:20, 12 января 2020 (UTC)
- fmac = floating или fused multiply–accumulate, так? Ни плавающего умножения форматов свыше 64 бита ни любого сложения форматов длиннее 64 бит нет, поэтому писать "два 256 разрядных FMAC блока", как мне кажется, не нужно. Среди результатов поиска "FMAC-256" АИ не вижу, только оверклукеры и форумы. Бывает two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC, но это скорее краткая запись для специальистов. Физически есть порт, который принимает данные из "векторного регистра" с какой-то шириной и операцию. Для fp mac (fused mac) операций внутри порта стоит multi-lane simd массив из скольки-то уможителей-сложителей (это число разное). Всяческие загрузки, логика и перемешивания это другие испольнительные субблоки за этим портом. Если какая-то avx-512 команда для вас выглядит как vpxorq z1,z0 это значит лишь что ее результат будет соответствовать спецификации; внутри порта она может исполнятся или много тактов или с разбитием на 4 lane. Дробные сдвиги могут быть работой нескольких 64 bit alu в разных lane с постобработкой и/или слабыми горизонтальными операциями. https://sites.utexas.edu/jdm4372/2016/11/05/intel-discloses-vectorsimd-instructions-for-future-processors/ "16 “lanes” of the 512-bit SIMD register, multiply the value in each lane by the corresponding value .. it is designed for Kazushige Goto‘s personal use."; https://www.linleygroup.com/mpr/article.php?id=11753 "lane masks for execution .. control which vector lanes are active"; intel US20140237218 "processor has 512 bits wide vector registers (i.e., vector width VW=512), each vector register can be divided into 8 “lanes,” with each lane 64 bits wide (i.e., VW/dw=512/64=8).", fig 3. Не знаю как именно лучше написать в статье FLOPS, если нам важно число операций в такт. `a5b (обс.) 00:06, 15 января 2020 (UTC)
А где в сокращенном обозначении "FMAC-256" явное указание на поддержку операций именно с одним операндом длиной 256 бит, а не вообще над 256 бит данных? Умножает и складывает за один такт? - да, значит FMAC. Может обработать за 1 такт 256 бит данных? - да, значит ширина блока 256 бит. Ну а всякие оверклокеры и форумы пишут так, потому что так пишут Intel и AMD на своих официальных схемах и слайдах. Например блок-схемы Bulldozer и Zen от AMD (128bit и 256bit FMAC) или подробнее схема Zen-1 (128 bit умножители и сумматоры отдельно, хотя внутри они тоже как 2х64 организованы) или Haswell от Intel (7й слайд - 256-bit FMA). Фуджитсу на схемах своих новых серверных ARM с поддержкой SVE SIMD тоже 512bit FMAC блоки рисует. Форумы и журналисты лишь за ними повторяют, особо не задумываясь. Реальность на самом деле сложнее, но не вижу смысла быть "святее Папы Римского" если сами разработчики железа считают нормальным использовать такие упрощения. А число операций в такт FLOPS вообще не зависит от того "честный" ли это модуль работающий с 256 битными операндами или же модуль работающий только векторами данных 4х64 8х32 и т.д., по крайней мере до тех пор пока речь не будет идти о вычислениях с точностью выше двойной. Максим (обс.) 23:01, 26 января 2020 (UTC)
{kind=link}
{kind=link}
{kind=link}